SPSS 10.0高级教程二:数据文件的管理(2)
2012-04-12 生物谷 生物谷

2.2.1.2 从原有变量计算新变量 从头定义变量的情况多数在建立数据集时出现。但是,当数据集已经建立,需要整理、转换变量时,碰到的更多情况是需要根据某种条件从原有变量计算新变量。下面williamhill asia 将按菜单条目的顺序依次讲解他们的功能。但是,首先williamhill asia 需要了解一下所用的对话框界面的情况。 【SPSS对话框元素介绍】 下面是williamhill asia 在第一章曾经见过的两样本t检验对话框: 这是一个非常典型的SPSS对话框
2.2.1.2 从原有变量计算新变量
从头定义变量的情况多数在建立数据集时出现。但是,当数据集已经建立,需要整理、转换变量时,碰到的更多情况是需要根据某种条件从原有变量计算新变量。下面williamhill asia 将按菜单条目的顺序依次讲解他们的功能。但是,首先williamhill asia 需要了解一下所用的对话框界面的情况。
【SPSS对话框元素介绍】
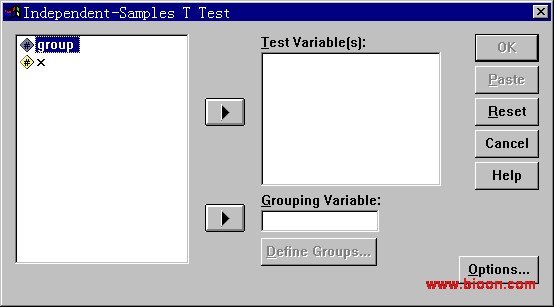
下面是williamhill asia 在第一章曾经见过的两样本t检验对话框:

这是一个非常典型的SPSS对话框。它包含了许多具有SPSS特色的对话框元素:
-
对话框左侧为候选变量列表框,里面列出了可被该对话框使用的变量;
-
右上方为Test Variables框,可将变量选入其中;注意在两个框的中间用“
 ”相连,这是变量移动按钮,其方向表明是将变量从那个框移动到哪个框,上图中williamhill asia
选中了变量group,两个移动按钮均变黑并向右指,表明变量group可以移动到他们右侧的两个框里去,改变当前框(在其他两个框里单击),移动按钮就会转向、变灰等以表明不同的意思(墙头草一个,可别小看这个功能,我想用VB实现这个功能,也是费了些工夫才把它搞定了);
”相连,这是变量移动按钮,其方向表明是将变量从那个框移动到哪个框,上图中williamhill asia
选中了变量group,两个移动按钮均变黑并向右指,表明变量group可以移动到他们右侧的两个框里去,改变当前框(在其他两个框里单击),移动按钮就会转向、变灰等以表明不同的意思(墙头草一个,可别小看这个功能,我想用VB实现这个功能,也是费了些工夫才把它搞定了); -
右侧为一排五个按钮,分别是确定、粘贴、重置、取消和帮助。这五个兄弟也是几乎永远一起出现的,另外四个大家都比较熟悉了,重置(Reset)按钮用于取消对话框内已做的选择,恢复到默认的状态;
-
最下方有个Options按钮,用于设置专门用于该对话框的选项;
-
OK、Paste两个按钮为灰色,表明所需条件尚未满足,该按钮暂不可用。同理,Grouping Variable框下方的Define Groups按钮为灰色显示,也表明暂不可用。
【Compute Variable对话框】
例3.2 在li1_1.sav中建立新变量temp,令其值当血磷值大于1时为2,否则为1。
解:这里需要用到Compute Variable对话框,外加一点技巧。首先给变量temp均赋值为1,然后将血磷值大于1的记录其temp变量值改为2即可。选择菜单Transform==>Compute,弹出Compute Variable对话框如下:

左上角为需要计算的变量名,在其中键入“temp”,此时“Type&Lable”按钮就会变黑,喜欢精确的朋友可以在这里对temp进行详细的定义,但如果你和我一样非常懒,就可以对它视而不见(不要生气,聪明人大多都非常懒:));左下方为候选变量列表,现在还用不着;中部为类似计算器的软键盘,可以用鼠标按键输入数字和符号,这里williamhill asia 直接输入“1”,输入的内容回立刻在右上方的数值表达式窗口中出现;软键盘右侧为函数窗口,可以在这里找到并使用所需的SPSS函数;这次也用不到。好,现在“OK”按钮已经变黑,单击他,系统就会自动生成一个新变量temp,并且取值均为1。
![]() 软键盘上几个奇奇怪怪的符号的含义如下:
软键盘上几个奇奇怪怪的符号的含义如下:
| ~= | & | | | ** | ~ |
| 不等号,等价于<> | 逻辑符号AND | 逻辑符号OR | 乘方,相当于函数EXP() | 逻辑符号NOT |
![]() 在函数窗口中选中某个函数并单击右键,系统就会弹出该函数的用法说明。
在函数窗口中选中某个函数并单击右键,系统就会弹出该函数的用法说明。
![]() 函数主要是和变量名组合起来使用的,比如说ABS(x)就是取变量x的绝对值。
函数主要是和变量名组合起来使用的,比如说ABS(x)就是取变量x的绝对值。
好,现在开始进行第二步,再次选择菜单Transform==>Compute,系统也再次弹出这个对话框--等等!注意到了吗?该对话框自动记住了你上次输入的内容,几乎所有SPSS的对话框都有这个特性,这会大大方便williamhill asia 的使用。好,将数值表达式窗口中的1改为2,然后单击中下部的“If”按钮,系统弹出记录选择对话框如下:

不需要太多解释,大部分内容都是前面见过的。由于williamhill asia
这里不是对所有记录做变换,因此选中第二个单选钮“Include if case statisfies confition:”,此时下方的所有窗口变亮,表明现在可用;而“Continue”按钮变灰,表明当前还没有提供所需的信息,好,williamhill asia
就来提供,在左侧选中血磷值(x),然后单击“![]() ”,x就被引入了右侧的变量框,任你用键盘或者用鼠标,总之将下面这个算式补充完:x>1。现在可见“Continue”按钮再度变黑。在它又变灰之前赶快单击它(开个玩笑),系统回到Compute Variable对话框,请注意If按钮右侧的变化:x>2。如果你做的结果不一样,请重来一遍。
”,x就被引入了右侧的变量框,任你用键盘或者用鼠标,总之将下面这个算式补充完:x>1。现在可见“Continue”按钮再度变黑。在它又变灰之前赶快单击它(开个玩笑),系统回到Compute Variable对话框,请注意If按钮右侧的变化:x>2。如果你做的结果不一样,请重来一遍。
现在单击“OK”按钮,由于williamhill asia 要替换变量值,系统会弹出一个确认对话框,确认替换,马上你就会看到,williamhill asia 已经把这道题做完了。
【Count对话框】
Count对话框用于计算某个值或某些值在某个变量的取值中是否出现(好象有点拗口),比如williamhill asia 想看看有哪些记录的血磷值在2~3之间,选择菜单Transform==>Count,系统弹出Count对话框如下:

Target Variable框中用于指定记录变量值是否出现的变量名,在这里输入temp2;选中血磷值(x),将其选入Variables窗口,此时“Define Values”按钮变黑,单击它,系统弹出变量值定义窗口如下:

左半部为变量值定义窗口,可以定义某个值、系统缺失值、系统或用户定义缺失值、变量值范围、小于某值或大于某值。williamhill asia 这里是第四种情况:选择Range,在through两侧分别键入2、3,然后单击已变黑的“Add”按钮,“2 thru 3”就会被加入“Values to Count”框内。然后单击“Continue”,再单击Count对话框的“OK”,可以看到系统自动生成变量temp2,其中10、11号记录因血磷值介于2和3之间,temp2取值为1,其余的记录temp2取值均为0。
![]() SOS,SOS,请大家千万注意,Count对话框有一个潜在的bugs,当你需要计算同时满足两个变量取值条件的记录数有多少时,直接用该对话框会得出完全错误的结果。这里有一点技巧,需要对对话框生成的指令加以修改,至于怎么修改嘛,williamhill asia
将在Syntax(语法)窗口使用详解一章中讲述 :)。
SOS,SOS,请大家千万注意,Count对话框有一个潜在的bugs,当你需要计算同时满足两个变量取值条件的记录数有多少时,直接用该对话框会得出完全错误的结果。这里有一点技巧,需要对对话框生成的指令加以修改,至于怎么修改嘛,williamhill asia
将在Syntax(语法)窗口使用详解一章中讲述 :)。
【Recode对话框】
Recode对话框用于从原变量值按照某种一一对应的关系生成新变量值,可以将新值赋给原变量,也可以生成一个新变量。
例2.3 在Li1_1.sav中生成新变量temp3,当血磷值小于1时取值为0,1~2时取值为10,大于2时取值为20。
解:选择菜单Transform==>Record==>Into Different Variables,Recode对话框如下:

将血磷值(x)选入Input Variable->Output Variable框,此时Output Variable框变黑,在其中键入新变量名temp3并单击Change,可见原来的x->?变成了x->temp3。现在单击“Old and New Values”,系统弹出变量值定义对话框如下:

许多东西和前面类似,不再重复。按照题目的要求,选择Range:Lowest through,在右侧框中键入1,然后在右上方的Value右侧框中键入对应的新变量值0,此时下方Add键变黑,单击它,Old->New框中就会加入Lowest thru 1->0,按照类似的方法依次加入另两条转换规则,最终Old->New框中共有Lowest thru 1->0、1 thru 2->10、Else->20三条,现在单击Continue,再单击OK,系统就会按要求生成新变量temp3。
![]() 哎呀不得了,图片太多了,虽然这样非常直观,但下载速度太慢了。等大家对基本界面操作熟悉了后,williamhill asia
将对比较简单的对话框试着对操作用文字的方式描述,比如上面的操作williamhill asia
将用文字表达为:
哎呀不得了,图片太多了,虽然这样非常直观,但下载速度太慢了。等大家对基本界面操作熟悉了后,williamhill asia
将对比较简单的对话框试着对操作用文字的方式描述,比如上面的操作williamhill asia
将用文字表达为:
-
Output Variable框:选入x
-
Output Variable Name框:键入temp3:单击Change钮
-
选中x->temp3:单击Old and New Values钮:
-
Range:Lowest through单选钮:键入1:New Value Value单选钮:键入0:单击Add钮
-
Range: through单选钮:两侧分别键入1、2:New Value Value单选钮:键入10:单击Add钮
-
Range: All other values单选钮:New Value Value单选钮:键入20:单击Add钮
-
单击Continue
-
单击OK
怎么样,还能理解吧。
【Categorize Variables对话框】
Categorize Variables对话框用于将连续性变量自动按要求分成等间距的几类。其界面非常简单,许多东西都是williamhill asia 所熟悉的,唯一特别的是右下方的number of categories框,用于输入变量的等级数,默认为4,比如williamhill asia 希望将血磷值按大小分成5个等级,先将血磷值选入Create Categories框,然后将下面的4改为5,单击OK,就会看到系统产生了一个新变量nx(即number of x之意),其取值就对应了血磷值相应的5个等级(1~5)。重复一下,具体操作步骤为:
- Create Categories框:选入x
- Number of categories框:5
- OK
【Rank Cases对话框】
例2.4 请分组计算血磷值的秩和。
解:选择菜单Transform==>Rank Cases,弹出Rank Cases对话框如下:

将血磷值选入Variable框,分组变量选入By框,单击OK即可。系统会建立一个新变量rx(即原变量名前加r表示Rank之意),其取值为x分组的秩次。
![]() 解释一下Rank Cases对话框的其他几个零件:
解释一下Rank Cases对话框的其他几个零件:
-
左下角的Assign Rank 1 to框架用于选择将秩次1赋给最小值还是最大值;
-
中下部的Display summary tables复选框用于确定是否在结果窗口内输出结果报表;
-
Rank Types钮用于定义秩次类型,有Rank(秩分数)、Savage评分(新变量值按指数分布)、Fractional rank(新变量值是秩分数除以非缺失值观测量的权重之和)、Fractional rank %(新变量值是秩分数除以非缺失值观测量数乘100)、Sum of case weights(新变量值是各观测量的权重之和)、Ntiles(新变量值是按所选变量的百分位数分组的组序号),默认值为Rank。单击More按钮,还会有更多的设置,这里就不再讲了。
-
Ties钮用于定义对相同值观测量的处理方式,可以是取平均秩次、最小值、最大值或当作一个记录处理,默认值为取平均秩次。
【Automatic Record对话框】
该对话框用于按原变量值的大小生成新变量,变量值就是原值的大小次序,功能和Rank Cases对话框重复(等价于相同值观测量当作一个记录处理的情况)。
【Create Time Series对话框】
用于自动生成时间序列变量,由于太专业,这里不做过多解释。
【Replace Missing Value对话框】
用于填充缺失值,结果存入一个新变量。填充方法有:序列的均数、相邻若干点的均数、相邻若干点的中位数、线性内插、线性外延,默认值为序列的均数。
2.2.2 数据的录入
2.2.2.1 直接录入
我想直接录入的问题就不用多讲了吧,直接敲就是了!
2.2.2.2 数据录入技巧
和其他常用统计软件相比,SPSS数据界面最大的优势就是支持鼠标的拖放操作,以及拷贝粘贴等命令,下面的数据录入技巧就是对这些功能的利用。
【连续多个相同值的输入】
如前面group变量有连续多个1,如果直接输入,可以在第一格内输入1并回车,然后回到刚才的单元格并单击右键,选择copy,最后用拖放方式选中所有应输入1的单元格,单击右键并选择paste,所有选中的单元格就会都被刚才拷贝的1填充。
【将EXCEL数据直接引入SPSS】
Excel已经打开原数据,并且数据量较少的时候,可以直接用拷贝粘贴的方法将数据引入SPSS:先在EXCEL中选中所有的数据(不包括变量名),然后选择拷贝命令;然后切换到SPSS,最好使行1列1单元格成为当前单元格,然后执行粘贴命令,数据就会全部转入SPSS,再定义相应的变量即可。
2.3 进一步整理数据文件--Data菜单
在许多情况下,williamhill asia 需要先对数据进行一些整理(如分组、合并、加权等)才能将其用于最终的统计分析。这些功能基本上都集中在Data菜单项中,下面williamhill asia 就对这些对话框做逐一介绍。
2.3.1 用于数据管理的菜单项
【Sort Cases对话框】
例2.5 对数据集li1_1.sav按group升序,x降序的次序排列。
解:选择菜单Data==>Sort Cases,系统弹出Sort Cases对话框,该对话框并不复杂,其中比较特殊的是下方的Sort Order单选钮,有升序和降序两种选择。请注意,该单选钮是和上方的Sort By框一起使用的,具体方法如下:
-
确认升序单选钮被选择,将Group选入Sort By框;
-
选择降序单选钮,将x选入Sort By框。

请注意:group和x后面分别跟着Ascending和Descending,表明前者是按升序、后者按降序排列;由于Group在前,因此排序时以Group优先。
【Transepose对话框】
该对话框用于对数据进行行列转置,可以在原数据文件中指定一个变量记录转置后的变量名。原变量名则自动保存在系统产生的名为case_lbl的字符变量中。
该对话框也非常简单,左侧为候选变量框;右上方为Variable框,用于选入需要转置的变量,一般应选入除名称变量外的所有其他变量,如果有变量未选入,则转置时会被自动丢弃;右下方为Name Variable框,用于指定原数据文件中记录转置后变量名的字符变量,但不是必需的,此时系统会将新变量自动按var001、var002...的顺序命名。
【Merge Files对话框】
用于合并数据文件,实际上包括了两个对话框,分别对应了两种合并方式:
1. 从外部数据文件中增加记录到当前数据文件中,称为纵向合并,用Add Cases对话框完成,相互合并的数据文件中应该有相同的变量。选择菜单Data==>Merge Files==>Add Cases,系统首先弹出打开数据文件对话框,选中需要添加的数据文件并按OK,系统才弹出Add Cases对话框,左侧显示的是新、老数据文件中不匹配的变量名,右侧显示的是已经匹配的变量名。可以用Rename按钮对不匹配变量改名(先选中)或用鼠标强行匹配(即先按Ctrl键选中匹配的两个变量再单击Pair钮)。右下方的Indicate case source as variable复选框用于定义一个新变量以区分哪些记录是后来添加的。选择停当后单击OK,该操作就完成了。
![]() 实际上右侧显示的是将要包括在合并后数据集中的变量,如果有哪个你不需要,把它弄到左侧框中即可。
实际上右侧显示的是将要包括在合并后数据集中的变量,如果有哪个你不需要,把它弄到左侧框中即可。
2. 从外部数据文件增加变量到当前数据文件,称为横向合并,用Add Variable对话框完成,相互合并的数据文件中应包含同样的记录。选择菜单Data==>Merge Files==>Add Variable对话框,系统同样先弹出打开数据文件对话框,单击OK后弹出和前面相似的Add Variable对话框。按需选择即可。
【Aggregate对话框】
用于对数据进行分类汇总,所谓分类汇总就是按指定的分类变量对观测值进行分组,对每组记录的各变量值求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件。

上图中各个零件的含义如下:
-
Break Variables框:用于选择分组变量;
-
Aggregate Variables框:用于选择被汇总的变量;
-
Name&Label钮:用于定义新产生的汇总变量的名称和标签;
-
Function钮:用于定义汇总函数,共有三组函数,以最常用的第一组为例,可选的函数有均数、同组的第一个观测值、最后一个观测值、同组记录数、标准差、最小值、和、最大值共8个;
-
Save Number of cases in break group as variable复选框:用于定义一个新变量以存储同组的记录数;
-
Create new data file单选钮:定义一个新文件以存储汇总的结果,右侧的File钮用于具体文件名的定义,默认文件名为AGGR.sav;
-
Replace working data file单选钮:用汇总的结果替换原来的数据。
例2.6 计算Li1_1.sav中两组的血磷值标准差。
解:该题完全可以用更简单的方法完成,这里只是演示一下汇总对话框的用法。
- Break Variables框:Group
- Aggregate Variables框:x
- Function钮:(Standard deviation单选钮:Continue钮)
- Replace working data file单选钮:选中
- OK
【Split File对话框】
用于将数据文件分组进行处理,该对话框williamhill asia 在第一章时已经使用过了,这里再介绍一下各个对话框元素的用途:
-
Analyze all cases单选框:和下面的两个单选框为一组,选中本框不拆分文件;
-
Compare groups单选框:按所选变量拆分文件,各组分析结果紧挨在一起便于相互比较;
-
Organize output by groups单选框:按所选变量拆分文件,各组分析结果单独放置;
-
Groups based on框:用于选择拆分数据文件的变量;
-
Sort the file by grouping variables单选框:将数据按所用的拆分变量排序;
-
File is already sorted单选框:数据保持原状,不按所用的拆分变量排序。
【Select Cases对话框】
很多时候williamhill asia 不需要分析全部的数据,而是按某种要求分析其中的一部分(比如只分析男性的身高、只对前200个数据进行分析以了解大概情况),这时使用Select Cases对话框可以大大简化工作。 该对话框界面如下所示:

其中主要的对话框元素为:
-
All cases单选钮:和下面的4个单选钮为一组,选中它则分析所有的记录;
-
If condition is satisfied单选钮:只分析满足条件的记录;
-
If按钮:和If单选钮一起使用,单击后弹出If对话框;
-
Random sample of cases单选钮:从原数据中按某种条件抽样;
-
Sample按钮:和Random单选钮一起使用,可以设定按百分比抽取记录,或者精确设定从前若干个记录中抽取多少个记录;
-
Based on time or case range单选钮:基于记录序号来选择记录;
-
Range按钮:和Based单选钮一起使用,用于输入记录序号范围;
-
Use filter variable单选钮:使用筛选指示变量来选择记录,必需在下面选入一个筛选指示变量,该变量取值为非0的记录将被选中,进入以后的分析;
-
Filtered单选钮:和下面的Deleted单选钮为一组,表示未被选中的记录只是被隔离,这些记录的记录号会被加上斜杠以示区别;
-
Deleted单选钮:未被选中的记录将被删除,一般不要使用。
当对数据集做出筛选后,所做的筛选将在以后的分析中一直有效,直到再次改变选择条件为止。同时在多数情况下,系统会自动产生一个名为filter_$的筛选指示变量,被选中的记录该变量取值为1,反之则为0。
【Weight Cases对话框】
在默认情况下,每一行就是一条记录,这在多数情况下没有什么问题,但有时却非常麻烦,想想看如果你需要计算一个四格表卡方,有100例,如果每一行就是一条记录,你就需要输入100条记录!如果希望在计算过程中利用不同的变量对数据进行加权处理,就需要用到Weight Cases对话框。该对话框的使用极为简单,界面上有两个单选钮,分别是不权重记录和用某变量权重记录,如果选择后者,则需要选中一个权重变量。
【Data菜单中的其余对话框】
-
Define dates对话框:可以自动生成时间变量。
-
Insert Variable命令:在当前列插入新变量。
-
Insert cases命令:在当前行插入新记录。
-
Goto cases对话框:到达指定记录号的记录,该命令在记录数极多时(1000条以上)非常有用。
2.3.2 正交设计菜单项
![]() 正交设计不包含在SPSS/BASE模块中,因此由于解密范围的问题,有的D版中不含该菜单项,不过我用的10.0版里是有的:)。
正交设计不包含在SPSS/BASE模块中,因此由于解密范围的问题,有的D版中不含该菜单项,不过我用的10.0版里是有的:)。
以前我以为SPSS不能作正交设计,感谢网友edof@sh的提醒,经研究,在SPSS中可以直接进行正交设计,Orthogonal Design子菜单项就是专门用于完成该任务的,具体做法用下面的例子说明如下:
例2.7 做A、B两个因素的正交设计,A因素有三个水平,B因素有两个水平。
解:选择Data-->Orthogonal Design-->generate,弹出的就是正交设计窗口,操作如下:
- Factor name框:输入A;
- 单击ADD钮;
- 确定变量A被选中,单击Define value钮;
- Value列:头三行分别输入1、2和3,代表变量A的三个水平;
- 单击continue钮;
- Factor name框:输入B;
- 单击ADD钮;
- 确定变量B被选中,单击Define value钮;
- Value列:头两行分别输入1、2,代表变量B的两个水平;
- 单击continue钮;
- 单击OK
在第10步定义完后,对话框应如下图所示:

在其他没有用到的选择项中,各种LABELS当然适用于定义相应的各种标签的;Data Files单选框组用来定义产生的数据文件是存为制定的文件名,还是直接替换当前工作文件;而Define Value对话框中的Auto fit框可以自动填充从1到你输入的那个数值这么多个水平的定义,特别适合我这种懒人。
这里williamhill asia 直接替换当前工作文件,在这个自动产生的正交设计数据集中,前两个变量就是要分析的A和B,各个水平已经按正交设计的要求排列好了。后面的status_和card_变量是系统产生的LOG变量,可以不管它。现在你再建立一个结果变量,输入实验结果,就可以进行正交设计的分析了。
本网站所有内容来源注明为“williamhill asia 医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于williamhill asia 医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“williamhill asia 医学”。其它来源的文章系转载文章,或“williamhill asia 号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与williamhill asia 联系,williamhill asia 将立即进行删除处理。
在此留言