
Cancer Discov:基于AI模型预测肿瘤何时会对化疗产生耐药性
2024-02-21 测序中国 测序中国 发表于上海

文章报道了如何利用机器学习算法来解决癌症研究面临的最大挑战之一:预测肿瘤何时会对化疗产生耐药性。
DNA复制是细胞分裂的一个重要环节。快速增殖是癌症的标志,也是DNA复制应激疗法敏感性的关键。大多数化疗是通过破坏DNA复制机制来发挥作用的,但许多肿瘤却表现出耐药性,其分子途径人们尚不完全了解。
由于不同肿瘤的药物敏感性和耐药性存在显著差异,治疗结果差异也较大,因此更好地了解反应的机制对于优化疗法至关重要。为此,人们对与复制应激诱导(RSi)药物敏感性或耐药性相关的基因改变投入了越来越多的关注和研究。不过,绝大多数基因改变在肿瘤中是罕见的,且不清楚这些基因是如何对药物反应形成整体的影响。
美国加州大学圣地亚哥分校的研究团队在Cancer Discovery发表了题为“Cancer mutations converge on a collection of protein assemblies to predict resistance to replication stress”的文章,报道了如何利用机器学习算法来解决癌症研究面临的最大挑战之一:预测肿瘤何时会对化疗产生耐药性。研究人员采用深度学习算法开发了一套预测模型,阐明了癌症突变如何影响癌症对常见RSi药物的反应,促进了多种药物的预测和机制解释。通过对肿瘤细胞的初步研究确定了41个分子组件(molecular assemblies),这些分子组件整合了数百个基因的改变,可以用于准确的药物反应预测。这些分子组件涵盖了在转录、修复、细胞周期检查点和生长信号传导中的作用,其中有30个通过功能丧失基因筛查来调节药物敏感性或复制重启。验证研究显示,该模型可用于预测宫颈癌患者的顺铂治疗反应。

文章发表在Cancer Discovery
研究人员生成并评估了RSi药物反应的可解释深度学习模型(图1B)。以肿瘤样本中检测到的基因变化作为起始,该模型预测了对特定RSi药物的敏感性或耐药性。这些模型的架构基于NeST(一个集成了相互作用关系和组学数据集的大型癌症蛋白质-蛋白质关联网络)中癌蛋白复合物的信息,也就是说,这些模型的预测结果可以从机制上产生解释,并对单药物和多药物模型进行评估。这些模型确定了一组蛋白质组件,这些蛋白质组件整合了基因改变来预测药物敏感性或耐药性。
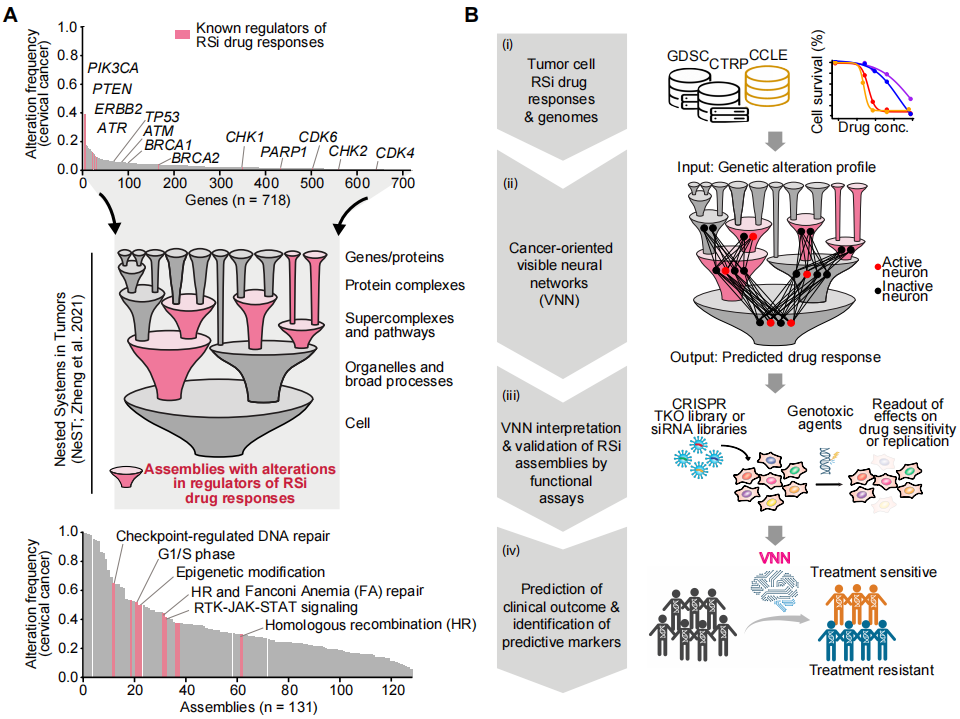
图1. 研究总览。
一、模型的训练和性能分析
为了模拟对RSi药物的反应,研究人员重点分析了由当前临床癌症基因组评估出的718个基因。将肿瘤样本中的这些基因改变状态作为模型的输入数据,包括突变和拷贝数畸变(CNA)的存在与否。研究人员使用来自癌症治疗反应门户(CTRP)和癌症药物敏感性基因组学(GDSC)数据库的基因组特征化肿瘤细胞系的药物反应数据,对模型进行了训练。这些数据库收集了对许多靶向DNA复制或DNA损伤反应的RSi药物反应,主要包括六种RSi药物(顺铂、吉西他滨、喜树碱、依托泊苷、奥拉帕尼、CD437)(图2A)。评估结果显示,在六个RSi药物模型中产生了2.2至3.2范围内的预测优势比(OR)(图2B,橙色点),这些模型表现出与现有模型相当或优于现有模型(DrugCell和DeepCDR)的性能。统一模型的OR为3.0至4.9(图2B,红点),显著优于单任务模型和对应的黑匣子模型。
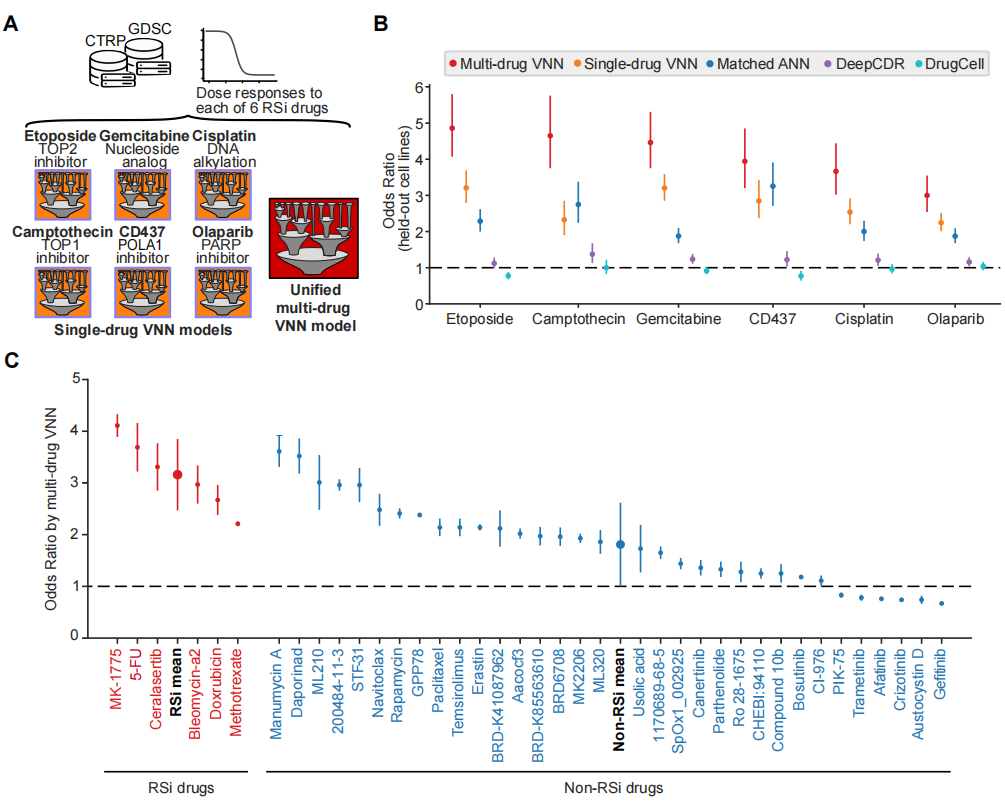
图2. RSi药物反应模型的性能。
二、分子组件对RSi药物反应预测很重要
接下来,研究人员依据系统重要性(SI)对所有蛋白质组件进行了评分,该评分衡量的是药物反应预测对分子组件内基因改变的依赖性。使用单药物模型创建了每个RSi药物的重要性分布,然后将其映射到NeST蛋白组件层次结构(图3A),多药物模型的系统重要性分布结果在质量上也与单药物模型一致。随着遗传信息的逐步整合,所有模型的重要性得分都倾向于随着层次结构中组件的大小和深度而增加。因此,为了着重于对RSi药物比较重要的蛋白质组件,研究人员重点研究了中小型组件(基因少于100个,共124个组件),并确定了41个在单药或多药RSi模型中得分较高的组件(图3A和3B)。与非RS药物相比,这些RSi组件对于预测细胞对RSi药物的反应特别重要(图3D)。
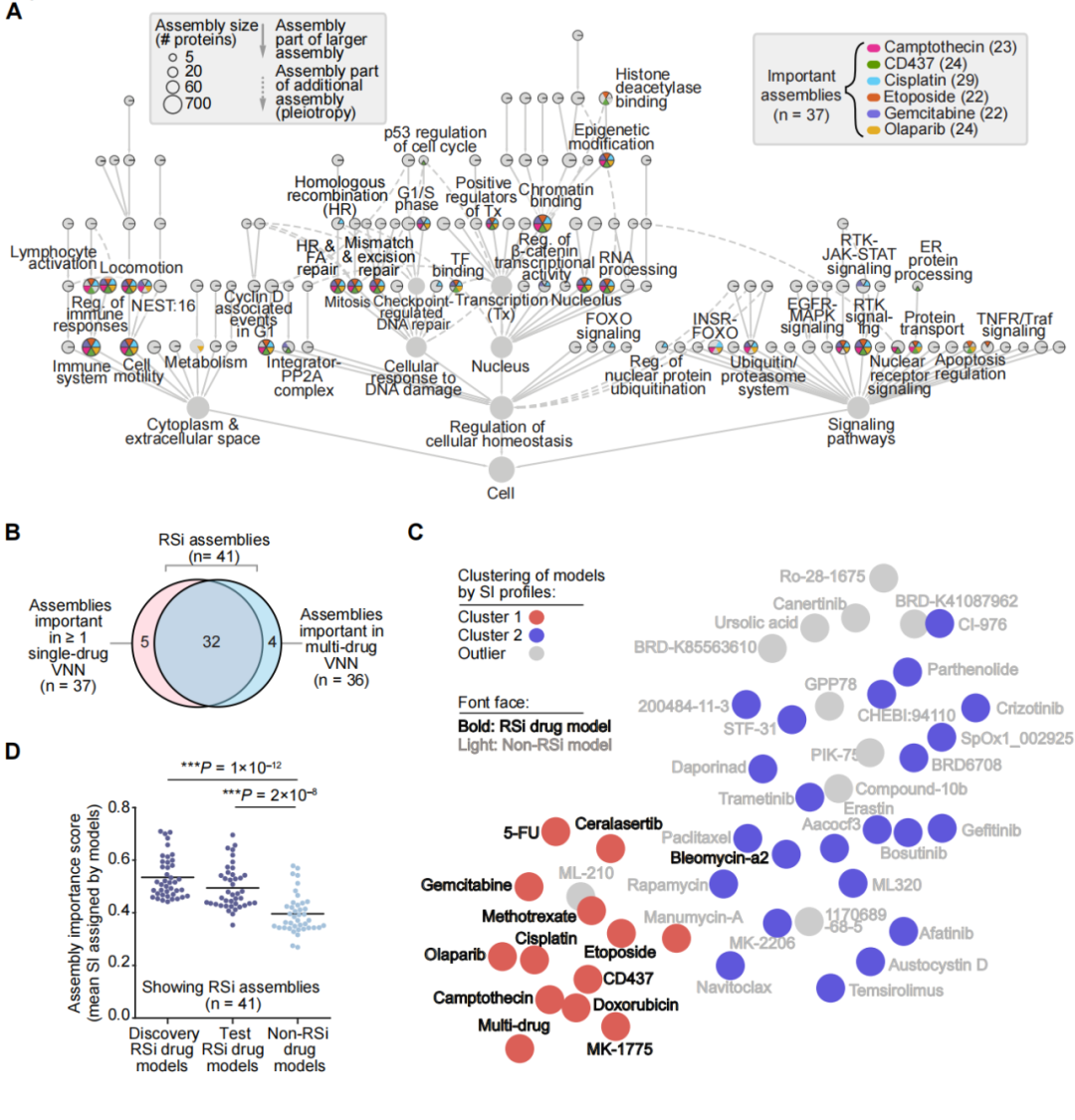
图3. RSi药物反应重要分子机制的鉴定。
三、顺铂临床反应的预测
在癌症基因组图谱(TCGA)分类的成人实体瘤中,有五种癌症亚型通常接受了顺铂治疗(每个亚型>30名接受顺铂治疗的受试者)。在这些亚型中,宫颈癌和肺鳞状癌(CESC和LUSC)患者显示出顺铂治疗的益处,但约35%的宫颈和肺部肿瘤在治疗后仍在继续发展(图4B)。顺铂的可视神经网络是否可以预测顺铂治疗后的不同转归呢?分析结果显示,顺铂治疗的CESC或LUSC患者如果被模型预测为对治疗敏感,其无进展生存结果明显优于那些被预测为耐药的患者。这种模型的预测性能明显优于基线随机森林或弹性网模型。
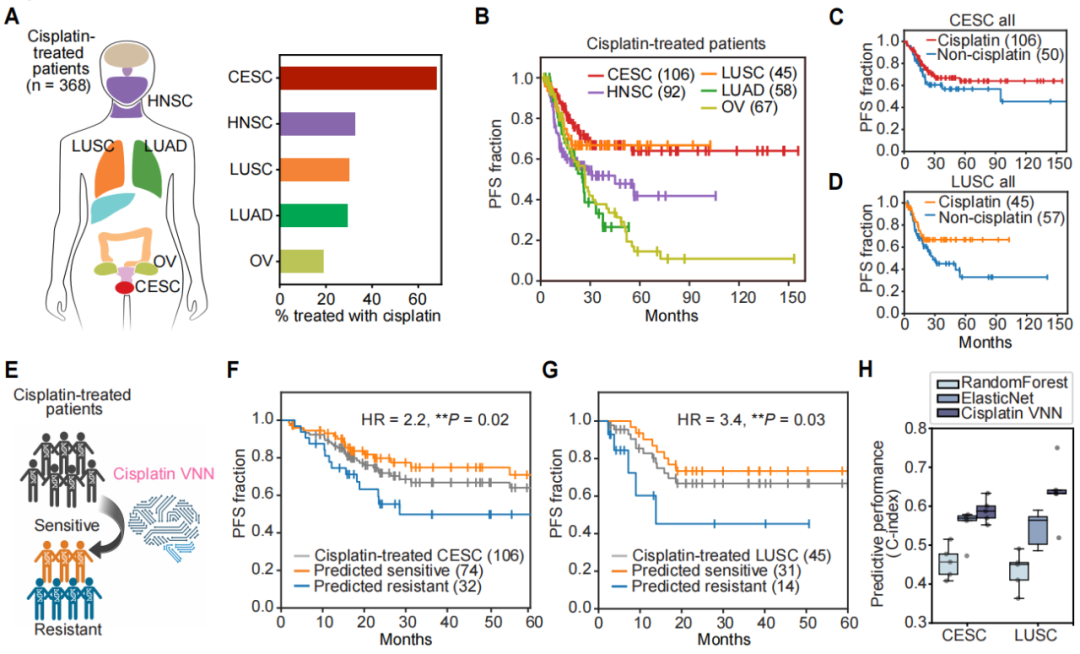
图4. 预测宫颈癌和肺癌临床结果的模型。
癌症是一种由许多相互关联组件驱动的基于网络的疾病,数百种蛋白质以复杂的排列方式协同工作来复制DNA,该系统任何一部分的突变都可能改变整个肿瘤对化疗的反应。该研究没有集中在一个单基因或蛋白质,新的机器学习模型评估了对癌症生存至关重要的更广泛的生化网络,揭示了肿瘤突变对DNA复制应激常见疗法的影响,由此产生的预测模型整合了分布在一系列分子组件中的众多基因改变,有助于对药物反应进行定量和可解释的评估。该模型的透明度是其优势之一,还确定了化疗的潜在新靶点,为增强癌症治疗策略和探索新的治疗途径铺平了道路。
文章通讯作者、加州大学圣地亚哥分校医学系Trey Ideker教授强调了人工智能在理解肿瘤内复杂相互作用方面的重要性。Ideker说道:“临床医生以前知道一些与治疗耐药性相关的个别突变,但这些孤立的突变往往缺乏显著的预测价值。这是因为数量更多的突变可以影响肿瘤的治疗反应。人工智能弥补了williamhill asia 理解上的差距,使williamhill asia 能够同时分析数千个复杂的突变矩阵。”
论文原文:
Zhao, Xiaoyu, et al. "Cancer mutations converge on a collection of protein assemblies to predict resistance to replication stress." Cancer Discov (2024). https://doi.org/10.1158/2159-8290.CD-23-0641
本网站所有内容来源注明为“williamhill asia 医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于williamhill asia 医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“williamhill asia 医学”。其它来源的文章系转载文章,或“williamhill asia 号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与williamhill asia 联系,williamhill asia 将立即进行删除处理。
在此留言













#肿瘤# #耐药性#
60